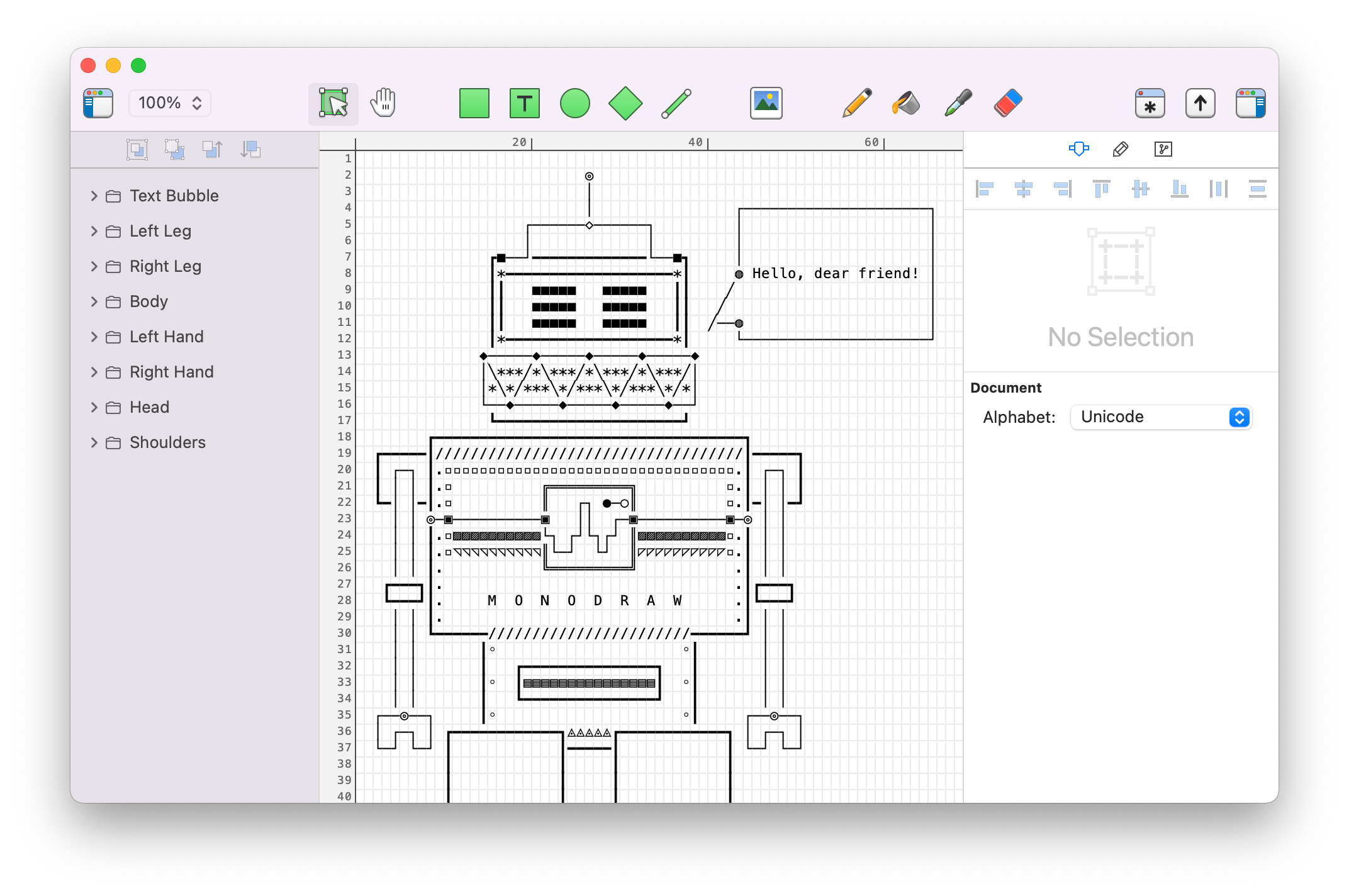
Decimal ozhoom from the forum sent me this AppleScript that you can hack to automate this process. Change the paths at the top.
# enter the folder location in quotes:
set path1 to "Users:john:xxxxxxxxxxxx" as alias
set path2 to "Users:john:P68 Personal Life" as alias
set path3 to "Users:john:xxxxxxxxxxxxx" as alias
set path4 to "Users:john:Downloads" as alias
tell application "Finder"
open path1
end tell
tell application "System Events" to perform action "AXPress" of menu item "New Tab" of menu "File" of menu bar item "File" of menu bar 1 of application process "Finder"
tell application "Finder"
activate
set target of front window to path2
end tell
tell application "System Events" to perform action "AXPress" of menu item "New Tab" of menu "File" of menu bar item "File" of menu bar 1 of application process "Finder"
tell application "Finder"
activate
set target of front window to path3
end tell
tell application "System Events" to perform action "AXPress" of menu item "New Tab" of menu "File" of menu bar item "File" of menu bar 1 of application process "Finder"
tell application "Finder"
activate
set target of front window to path4
end tell
We're refreshing the website and replacing as many of the images as we can with line art diagrams. This fits the vibe better, they're easier to maintain, and they're hundreds of bytes instead of tens of thousands.
Lucy is using the delightful Monodraw for this and I thought I'd give it a shout-out. If you have any need to draw ASCII diagrams and you're on a Mac, you'd be mad not to use it.
There's a free trial, and it's ten measly dollars to buy.
Figure 22.00.0191A. Monodraw (image from their website).
I've been thinking a lot about 'this time last year'. It was a period of upheaval for us, but also of huge productivity.
We were madly selling everything we owned on Gumtree and getting ready to move out of our home of 5 years. And we'd set a hard deadline that the Small Business System (SBS) had to be released by the end of March.
A year ago, I was buried in a looong document. For reasons, this was also a very sad time. And while it sounds cliched (and I'm no workaholic), I was grateful to have work to bury myself in. Johnny was nearby figuring out the code to make a website with a login.1 I'm pretty sure I saw steam coming out of his laptop from time to time.
Break to stand at the whiteboard and discuss something. Write more words. Break to pack a moving box. Write more code. Break to run outside and help the buyer of our pot plants load them into a trailer. Back to the whiteboard. And so it continued.
In a nutshell, here's how we made it.
The process
We followed our own advice and stuck to the process in the Workbook/Workshop.
Scope
Our scope statement was basically "try to think of everything a small business has to do". We drew on our combined 40+ years of experience and also tested our ideas on a list of about 20 different business types. We defined a small business as fewer than 10 people, roughly.
Discovery
I opened the first of many blank mind maps and started reading different business and tax websites from the Australian Government. I pulled out keywords on anything to do with starting a small business.
Then I reviewed:
Everything in my archived filesystems from when I was a freelancer (Johnny did the same).
Everything in the Johnny.Decimal business filesystem and JDex.
Some filesystems and feedback from real small businesses in the US and New Zealand.2
I wrote down as many things as possible. I sat and thought. I walked and thought. I went down many research rabbit holes. I printed out a 20-page business plan template, stuck it to a wall, and stared at it many times a day. This went on for a few weeks.
Figure 22.00.0190A. An inspirational government business plan template on our wall.
Creating areas and categories
Then it was time to start grouping the 'discoveries' into areas and categories. And having Big Discussions with Johnny at the whiteboard. During this time, we also got up at 5am every day for Big Discussion Walks around our neighbourhood with mugs of coffee.
The mind map began to take shape and grow.
Figure 22.00.0190B. The SBS areas and categories in progress.
Building the system
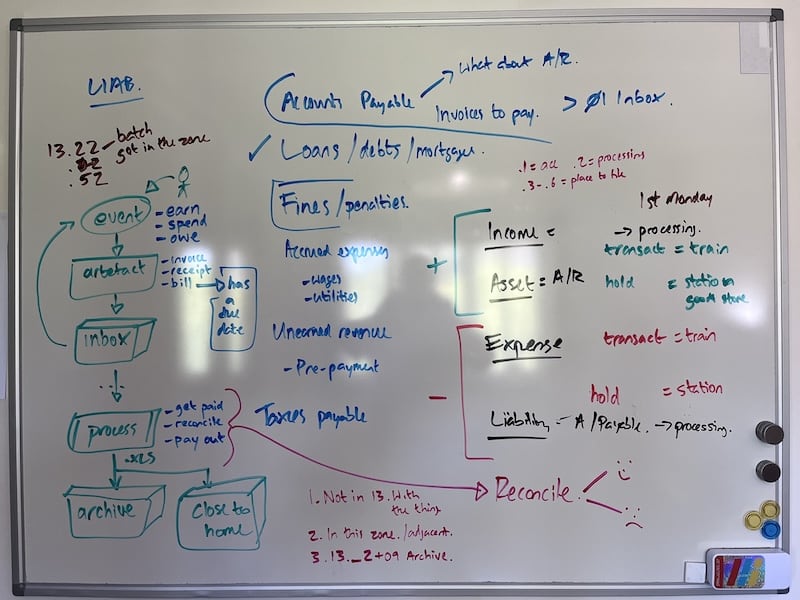
This was a very collaborative process and Johnny spent a lot of time riding the whiteboard:
I took notes, photos, and audio recordings of our conversations.
We named the IDs and wrote the descriptions.
We numbered the IDs only after much consideration.
Then I wrote the supporting words for each ID.
Figure 22.00.0190C. Figuring out the finance category.
ID by ID, we began at the beginning and kept going until we reached the end. There were several rounds of review and feedback on mind maps and my master document.
When the content was 'approved', I pasted it into hundreds of text files to become the website. More rounds of review of the website followed. By the end, we were both quite batty and delirious.
Figure 22.00.0190D. Putting Johnny's feedback and other edits into the master document with a Friday-evening martini.Figure 22.00.0190E. Proofreading the master document at the kitchen table before turning it into the website.
Final stats
A quick review of our archived files shows:
Our new system had 5 areas, 21 categories, and 344 IDs.3
There were 13 research and planning mind maps.
The master document had 342 pages and 46,309 words (written in Markdown).
Johnny had written 13,000 lines of code.
The project lasted 6 months, from September 2024 to March 2025.
We also did a sticker mailout to the first 100 people around the world who bought the system before it was released. Thank you for trusting us!
Figure 22.00.0190F. The pre-release sticker (Johnny loves planes) – we're still repping ours.
Everything related to this project was made with sweat, tears, and love by two humans.
What now
We're really happy that we made this system. We'd talked about making something for small business for ages, we just weren't sure where to begin. We spend all day in ours and we hope it's helped other businesses feel more organised.
We have ideas for improvements and welcome feedback. In the meantime, there's a new YouTube playlist for videos on how Johnny uses the SBS.
And, finally, a special shoutout to Genesis and the inventor of the martini, without whom this project would not have been possible.
Footnotes
Versus a one-off download and PDF from Shopify as per the Life Admin System v1.0. ↩
Thank you Dan from Paparonis, Des from Datum Machines, and Jeff from Lovett Sundries. And any other Decimals who were in touch on the forum, Discord, or email. 😊 ↩
Not including all the standard zeros throughout. ↩
Soon enough I'll be releasing JDHQ v26 which will allow you – if you so choose – to store your own data. Think textual data: notes, the titles of IDs and categories, that sort of thing.1 (I have no plans to build a file storage service.)
But data is data. Even the title of an ID you create is potentially sensitive: it might relate to a medical procedure, for example.
It would be disastrous to leak or otherwise allow this data to be exposed. There's the obvious moral motivation, but also an economic one: nobody's going to pay to use an insecure platform!
I'm particularly sensitive to security issues given last month's leak of email addresses. So here's an in-depth look at my security practices. In the hope of making it readable by the layperson, I'll give background where necessary. I welcome feedback.
Background: secret keys
My site uses a number of third-party services. Of particular interest are Clerk, which handles authentication, and Supabase, where your data is stored.
Use of third parties like this is not only normal, it's encouraged. Authentication in particular is notoriously difficult: it's the sort of thing I really shouldn't do myself. It's very likely that I'd do it wrong and introduce a security hole. Far better to use a company whose entire focus is authentication. So you should see this use of third parties as 'a feature, not a bug'.2
My site runs on Netlify and for Netlify to talk to Clerk or Supabase, it needs my 'secret key' from those services. This is just a very long password that servers use to talk to each other. But there's a clue in its name: secret. If you have my Clerk or Supabase secret key, you can do anything that I can do.
We'll come back to these secret keys.
My logins to these sites
If you could sign in to these sites as me, that'd be bad. You could generate new secret keys, for example.
All of my logins use unique email addresses at a never-published domain (i.e. not …@johnnydecimal.com), unique strong passwords generated by 1Password, and 2-factor authentication.3
Background: encryption
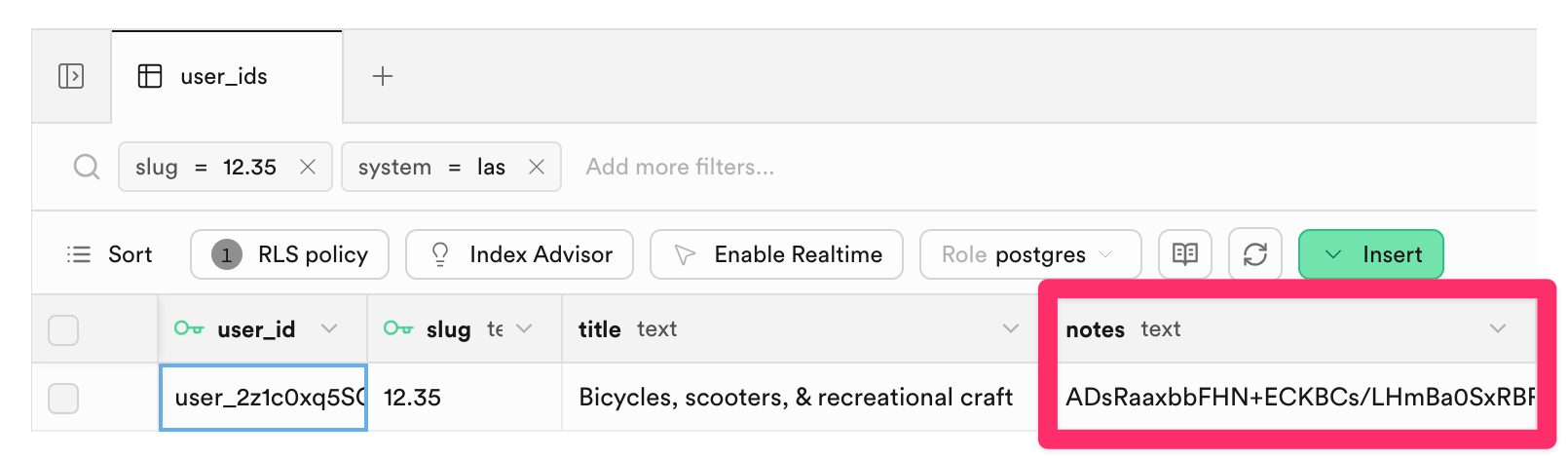
If I didn't encrypt your data, I'd be able to trivially – and accidentally – read it. Here's what the Supabase console looks like.
Figure 22.00.0189A. Supabase table view.
I've highlighted the 'notes' field. If that wasn't encrypted, any notes you entered would just appear there. Similarly for the title of your custom ID in the column to the left.4
Encryption is a balancing act. Broadly, there are two options.
I encrypt it with a key that I hold. I can decrypt it.
I encrypt it with a key that you hold. I can't decrypt it.
You might think option 2. is the obvious choice, but it comes with a serious drawback: if you lose the key, there's nothing I can do to help you decrypt your data. It's irretrievably lost. And overall it's just a more complex solution with more moving parts; more to go wrong.
For this reason, the vast majority of services that you use hold a key to your data. Apple has a key that will unlock your iCloud account: otherwise when you drop your phone in the ocean and realise you've also forgotten your iCloud password, all your family photos are gone. (This happens all the time.)5
The data encryption key
This encryption key is basically another secret key: a very long 'password'. I'll explain below how I ensure the safety of these keys.
The data encryption algorithm
I use AES-256-GCM. AES-256 is the gold standard for symmetric encryption. The 'GCM' part adds authentication: not only is your data unreadable without the key, but any tampering with the 'ciphertext' (the encrypted end result) is detected. If someone were to modify your encrypted data in the database, the system would reject it rather than silently returning garbage.
Each time a piece of data is encrypted, a random value is mixed in. This means that even if two users enter identical notes, the encrypted result is completely different each time – an attacker looking at the database can't even tell which entries contain the same text.
Your name isn't stored alongside your data
Note the user_id field in that screenshot. This id, which is a very long random string like user_39FY886j223z4M3jAib2ZRwcM3H, is how your data, in Supabase, is linked to your user, at Clerk.
So in order to steal your data and link it to your identity, an attacker would need to:
Steal the Supabase database.
Steal the encryption key, to decrypt the data.
Access my Clerk account, to link the stolen data to an individual.
This assumes that I even have your name. You can save it in your JDHQ profile, but it's optional. I encourage the use of email aliasing for further anonymity.6
You need to trust me
This whole thing implies a level of trust. Just like you trust Apple not to go rummaging about in your iCloud account, you need to trust me to not decrypt your data just because I'm curious. To make it explicit: I won't do that. That'd be creepy and, again, business-ruining if discovered. What would I possibly stand to gain?
I am subject to the laws of Australia
Like every other service you use, I am subject to the law. Holding a key to your data means that, if legally compelled to reveal it, I am able to do so. This is just something to be aware of.7
'Advanced data protection' in the future
I would like to add an ADP-like feature – where you supply your own encryption key – in the future. Given the nature of my site and the data stored on it, it's honestly not high on my list of priorities.
Implementation details
The TL;DR of the background story so far is that:
I hold a number of keys that are vital for the running of the service.
These keys are critically sensitive. If leaked, stolen, or lost: game over.
Here's how I protect those keys.
Loading them into consoles
There is a one-time action which is to:
Retrieve the secret key from its service, e.g. Clerk, or
Generate a secret key, e.g. for data encryption, then
Load that secret key into the consuming service, e.g. Netlify.8
It is in my interests to make these keys as difficult to access as possible. Fortunately, after this one-time load, I never need to access them. I'd only need them if, say, I moved from Netlify to another host.
I also need to not lose them
This is another trade-off. While keeping these keys very secure, I need to ensure that I don't lose them. While I can regenerate Clerk's secret key, this isn't an option for the key that encrypts your data. If I lose that key, I lose the ability to decrypt your data: also disastrous.
1Password
It is standard practice to store keys in a password manager. 1Password is one such tool. I've used it for my own passwords – which are all unique – since 2009. It provides dedicated features for developers.
Production keys
Production keys – those that are used to secure your data – are stored in a dedicated 1Password vault. Given that I do not routinely use these keys, I have removed my user account's 'read' access from this vault.
This causes the vault to un-synchronise from the desktop application. As a result, these keys are no longer available on this laptop.
This prevents even the most nefarious process from accessing them. Even if I were tricked into unlocking my vault: the keys simply aren't there to read.
To re-synchronise the vault to this laptop I need to sign in to the 1Password web console and add 'read' access back to my account. This would be a very deliberate action and certainly not one that a nefarious script could perform.
Development keys
This gets a bit technical.
My development keys – which I need to have available to me on this laptop, but which are not used to secure your data – are stored in a vault that is synchronised to this laptop. I have created a service account that only has access to this vault.
These keys are made available to my development environment using secret references in my .env file.9 For example:
Because my 1Password service account token is available to my environment, development key requests do not trigger a fingerprint authentication request.
This prevents 'fingerprint fatigue'. Previously, every key request triggered 1Password's authentication pop-up. It was natural to instinctively respond to these requests and would have been easy, therefore, to over-respond and accidentally approve a nefarious request.
Now, if a nefarious actor somehow triggers an op read request, 1Password will prompt me. This prompt will be unexpected and unusual; I will not instinctively reach for the fingerprint sensor. Not that it matters: because, as noted above, production keys aren't even here. There's nothing to steal.
This layered approach protects against supply-chain attacks like this one from 2025.
Key rotation
'Rotation' is the practice of proactively getting new secret keys and re-loading them into consoles. It's standard at large companies where many people might have access to a key: it limits the exposure if you forget to remove someone's access after they leave, for example.
I have no plans to routinely rotate my keys. For an individual with the controls described above it adds operational risk without any meaningful benefit. When am I most likely to accidentally leak a key? When I'm handling keys. So the less I do that, the less the risk.
Trufflehog
I have installed Trufflehog as a GitHub action. This software 'sniffs out' any secrets that are accidentally committed and pushed to GitHub (i.e. a worse version of what I did with those email addresses).
Every push to JDHQ is scanned by Trufflehog.
Package updates
Modern websites use any number of third-party software packages, and those packages are a source of security vulnerabilities. It is important to keep them up-to-date.
I have a monthly checklist to update all packages. I protect against malicious updates using pnpm's minimum-release-age and blocking of post-install scripts. This means that a package can't be installed until at least one week after its release, giving the community time to discover and flag compromised versions.
Phishing
You can have the best key security in the world, but if an attacker tricks you into handing them over – by setting up a fake site, and luring you into entering them there – it's game over.
Using a password manager, and only ever using it to fill your passwords – never entering them manually – is the simplest way to avoid having your credentials phished.
Because 1Password knows that my Clerk password only belongs at https://clerk.com. When a phisher tries to get me to sign in at https://сlerk.com – look carefully, see if you can spot the scam – 1Password will refuse to enter my password.
Passkeys are an even stronger defence against this, and I use them for all of my sensitive services.
Browser behaviour
Behaviourally, I have another line of defence. In this video I show how I have my common sites permanently set up in Safari tab groups.
So if someone mailed me a link to sign in to Clerk, I wouldn't click that link. That would open a new tab in a new window, which would break my neat system. Instead, I already have an open tab for Clerk, in my ⚙️ Services group. I'd head over there and look for a notification.
Disclosure and feedback
If I ever discover a security issue I will disclose it within 24 hours on the blog. Posts appear in my RSS feed, and I cross-post to the forum, Discord, and Mastodon.
Security.txt
I welcome security feedback and publish a security.txt.10
Summary
I'm very, very comfortable with my security posture. I've written it up here for a few reasons. It forced me to consider the end-to-end approach. I hope it gives you confidence. I hope you learned something. And I hope that other solo developers might find these patterns useful.
Versions of this post were kindly reviewed by two 'friends of Johnny.Decimal' who work in the field of IT security. Thank you. Any errors or omissions are, of course, my responsibility.
100% human. 0% AI. Always.
Footnotes
This will be a very early beta-style release. I expect almost nobody will use it. But the only way for me to get this thing from no-product to useful-product is to build it, and start using it. So that's what I'm gonna do. ↩
A phrase that nerds use to mean something that's working as designed. ↩
I implement Passkeys where available, otherwise using one-time codes managed by 1Password. I don't use SMS authentication.
I own a YubiKey but given my physical situation – travelling the world, always on the move – the risk of losing it outweighs any benefit I feel it would give. ↩
This ID is one of the base set from Life Admin and as such its title doesn't need to be encrypted. ↩
Apple offers Advanced Data Protection for those who want to opt-out of this key recovery. Most people shouldn't use it. ↩
I'll be recording a free course with Lucy later in the year to explain how this works, and how to set it up yourself. ↩
I'll implement a warrant canary before the new site goes live. ↩
Last week it was my pleasure to have A Productive Conversation with Mike Vardy. We talked about the origin story of Johnny.Decimal, and why there's room for plenty more systems in the productivity world; about the links between my system, task management, and Mike's concept of TimeCrafting; and about content vs. context, and how we're often better off starting with the latter, even though our instincts start us with the former.
Yesterday I discovered that I had leaked 3,638 email addresses by uploading them to a public GitHub repository.
Here's what happened, how it happened, what I did about it, and what I'm doing to make sure it can't happen again.
TL;DR
This post will be long, so here's the essential stuff if that's all you care about.
Yesterday morning (2026-03-03 06:00 -- all times in this post are UTC) I was alerted by email and private message that someone's unique email address, that they had only ever used on my services, had received a phishing email purporting to be from PayPal.
There's only one way for this to be possible: it meant that I had allowed the address to be stolen. I acknowledged this with a blog post at 06:46, requesting that people let me know if they were affected.
Through the day I received, or could infer from my own data, 17 addresses that either did, or did not, receive the phishing email.
Analysis of these 17 data points led me to the realisation that I had uploaded a folder full of text files containing email addresses to a public GitHub repository. This made them visible to anyone who cared to go looking. I confirmed this theory at 18:00 and immediately made the repository private. I acknowledged this with a blog post at 18:18.
The first upload of 1,650 addresses occurred on 2024-10-08. Further updates were uploaded through 2025. The final number of addresses in the repository was 3,638. Because I don't know when the data was scraped from GitHub, I can't be sure which of those addresses was harvested. My assumption must be that they all were.
I am deeply sorry. I strive every day to be an exemplar of 'the good Internet'. In this instance, I have failed you quite miserably.
How to determine if your address was leaked
Immediately after this post has been published I will email the 3,638 addresses that were leaked.
Subject: Important: your email address was exposed [D25.14.44]
If you receive this email then your address was leaked.
You can also check if you received the phishing email:
From: PayPal Security <no.con**star@ca**a.cl>
At: around 2026-03-03 05:30 UTC
Subject: Please confirm your identity
If you receive this email then your address was leaked. (Check your spam folder: many providers correctly identified it as a phishing attempt.)
If you do not receive either of these emails then your address was not leaked.
Was any other data leaked?
Like names, addresses, dates of birth, passwords, or access to accounts?
No. The only data leaked was a list of email addresses in a text file.
What's the impact of the leak?
The email address that was leaked will receive spam and phishing attempts.
To be clear, your account has not been compromised. Only your email address has been made public. You do not need to change your password (assuming it is already unique -- see What can you do? at the end of this post).
Here's why I had a folder full of your email addresses, and how they ended up on GitHub.
Over the years I've used a variety of 3rd party platforms to deliver websites and services, as well as hosting a public email list.
Buttondown
Used to host the mailing list from 2019–2024.
Allowed users to opt-in to email marketing.
Users hold an account of sorts; while you don't have a password, the platform records your email address.
Netlify
Used to host johnnydecimal.com and jdhq.johnnydecimal.com from 2019–current.
Users do not hold an account at Netlify: it's an infrastructure service only.
Gumroad
Used to sell the Workbook from 2023–2024.
Allowed users to opt-in to email marketing.
Users held an account at Gumroad.
Thinkific
Used to sell various products from 2023–2025.
Users held an account at Thinkific.
Shopify
Used to sell various products from 2024–2025.
Allowed users to opt-in to email marketing.
Users held an account at Shopify.
Stripe
Used to process payments from 2024–current.
Users hold an account of sorts at Stripe: you can't log in, but they hold a record of transactions linked to your email address.
PayPal
Used to process payments from 2024–current.
Users may hold an account at PayPal.
It's also possible to check-out as a guest, but in any case your email address is recorded.
Listmonk
Used to host the mailing list from 2025–current.
Allows users to opt-in to email marketing.
Users hold an account of sorts; while you don't have a password, the platform records your email address.
The link at the bottom of every email allows you to unsubscribe (in which case your email address is retained) or delete your data entirely.
PikaPods
Used to host Listmonk from 2025–current.
Users do not hold an account at PikaPods: it's an infrastructure service only.
Amazon Simple Email Service (SES)
Used to send emails from 2025–current.
Users do not hold an account at Amazon: it's an infrastructure service only.
Clerk
Used to host JDHQ user accounts from 2025–current.
Users hold an account at Clerk.
If this sounds like a nightmare, it's because it is. But this is the reality of running a small online business: you stitch together that business based on the services available to you at the time. This is a factor of features, cost, and experience. As your business grows, you move between platforms.
To be explicit: none of this is the fault of any of these platforms. I list them all merely to demonstrate the range of stuff one has to deal with.
The reality of running this type of business is that you spend a lot of time consolidating user data from these services. Why is this person in this data set and are they the same person as this person in that data set? You do this so you can mail the right people the right information; send subsets of people offers that are only relevant to them; migrate user accounts from old platforms to new platforms.
As a small business with limited resources there's only one practical way to do this analysis: Excel. In a bad month I might spend 50% of my time 'mashing' data like this. I hated having to do it, and eliminating it was a very strong driver in my building JDHQ: because now you have a single account, forever. No more mashing of CSV files exported from half a dozen platforms.
(Ironically, this leak is partially a result of my very, very strong desire to never send anyone an email that they don't want. I've spent dozens of hours over the last few years meticulously poring over and cross-referencing this data, taking pains to ensure that someone who opted out on this platform didn't get opted back in on that platform. Had I not bothered, some of this data might not have been on my laptop. C'est la vie.)
So we have a folder full of CSV files
That's where we are in the story: I have a folder full of CSV files from these various platforms that I've been using to consolidate and migrate accounts, and to send email directly from my laptop via Amazon SES.
So how did they end up on GitHub? Sheer stupidity.
This repository started on 2024-01-10 as an intentionally-public archive of emails sent to the mailing list. It contained 3× text files.
The problem started on 2024-10-08 when I started to use the same folder to store the output from these CSV files.1 Forgetting that the linked repository was public, I committed these files and 'pushed' them to GitHub. At this point they were available publicly.
Why this git/GitHub thing?
It's natural to use git -- which is software independent of GitHub, the website -- to manage a dataset like this. It gives you version control, which is really useful. If you mess up, you can just 'roll back' to a previous state.
Using git locally isn't the problem. Not realising that the linked GitHub repository is public and pushing to it was the fatal mistake. I'll address this below.
From 2024-10-08, this folder, which lives at ~/dev/amazon-ses on my laptop, continued to be used as a place where I stored lists of email addresses so that I could send email via Amazon SES. Every time I did that, I committed the changes and pushed them to GitHub. And so by yesterday, the repository held 3,638 unique email addresses.
My own password hygiene
So that I don't need to make the point below with regards to each specific service, I'll make it here.
I have exclusively used 1Password for password management since 2009. All of my passwords are unique and they exceed all modern standards for entropy. Where 2FA is an option I always enable it.
It was, at least, nice to know from the start that this leak wasn't the result of bad password management.
My 'secret key' hygiene
Separate from passwords, developers of sites like mine have 'secret keys' that are used by servers and services to talk to each other. From JDHQ, for example, you can opt-in to product notification emails. This is possible because the service that serves JDHQ, Netlify, has the secret key for Listmonk and can talk to it directly via the software I've written. If you have the secret key for a service, you can read all of the data contained therein.
I was already planning an article detailing the steps I take to secure these keys, so I'll just note here that they're also all stored in 1Password, and that I had already taken what I believe to be extraordinary lengths to secure them against attack. More to follow.
Listmonk and PikaPods
I 'self-host' my mailing list using Listmonk hosted on a PikaPod.2 At 06:31 I identified that the Postgres instance used by Listmonk was open for login using a public console. This isn't enabled by default: I had turned it on a few months earlier so that I could connect directly to the database using client software on my Mac.
Forgetting to disable that access was definitely a mistake -- see action 4, below -- but the risk seemed low. The username and password are set by PikaPods and both were secure: the username not being admin or similar, and the password being a 24-character string. Checks of the console software, Adminer 5.4.2, showed no vulnerabilities.
For these reasons, I dismissed the possibility of a leak via this route. Because I was so sure that this wasn't the cause, I didn't email PikaPods until 15:36. Finally doing so, I asked them if there were any logs for this console endpoint that might be useful.
Their reply just 45 minutes later was stunningly helpful, clearly written by a caring human. I could not have recommended them more before this happened, and yet here we are, my endorsement stronger than ever. A superb service, utterly without fault.
At this point (16:13) I hadn't positively eliminated this as the cause, but it seemed vanishingly unlikely.
Buttondown
Early data supported a theory that Buttondown's service had been compromised. As a reminder, they hosted my mailing list from 2019–2024. So it's not unusual that there was a 1:1 match between leaked email addresses. I mailed their support at 08:57 emphasising:
"This is NOT an accusation -- I'm trying to figure this out myself. It's purely FYI, and I genuinely hope for you that I'm wrong."
– thinking that, if a leak had occurred, their support might appreciate the data.
Through the day I continued to receive data points, none of which disproved this idea. This analysis was basic science at work: build a hypothesis, collect data, see if data supports hypothesis.
Of course good science is about a falsifiable hypothesis, and at 15:31 I was made aware of 3× addresses that had received the phishing email that were not in my Buttondown exports. It was a relief to rule them out as a cause and I notified them immediately.
Again, I can't sing the praises of a company enough. Anita from Buttondown support felt like a friend yesterday, keeping in touch even after I informed them of this finding. If you need an email newsletter, use Buttondown. They're truly good people.
How I came to the answer
Around 16:30 we went for our usual end-of-the-day walk. Still not knowing the cause, I replayed all of this to Lucy. Thoughtful questions followed and, via this conversation, the thought occurred to me. Back to science, this is Occam's Razor in a nutshell: given all possibilities, the simplest should be considered the most likely.3
The simplest possibility being that I, as a holder of all of this data on my laptop, committed it to a public repository. Getting home, this was confirmed at 18:00.
A note on the data sources involved
You might be on this list despite having never signed up for my mailing list. For example, hundreds of email addresses from JDHQ members are impacted. Those addresses aren't on the public list, because I never sign you up without your explicit opt-in.
These addresses are in the data because I used the leaked scripts and Amazon SES to send transactional emails as well as marketing emails to the public list. Similarly, addresses from previous platforms may be present.
Lessons learned
Looking out of the window earlier this week I saw a fire engine, sirens blaring, scream up behind a learner driver. Should be part of your driving test, I thought. Because you can't truly be prepared for the panic induced by sirens a metre behind you until it happens.
In a way, I'm glad this happened. Without trying to minimise the event, it's fair to say that on the spectrum of security and data leaks, this is about as benign as it gets. Better that this happens now when I can learn from it, than a much worse event happens later.
Because if this hadn't happened, I would have spent the day developing JDHQ, where you'll soon have the ability to store your own notes, and create your own IDs.4 It is impossible to convey the depth of responsibility I feel for this data. I lie awake at night thinking about how to keep it secure. (An enjoyable problem to solve, to be clear.)
Like I said above, I've already been planning a post addressing this data and the measures I'll take to protect it. So here let's just talk about what I learned yesterday.
If you don't have it you can't lose it
I can't stress enough that I do not want your personal data. Having it means having responsibility for it: and then look what happens.
You may notice that I don't ask for your name when you sign up for JDHQ. Requiring a name is an option at Clerk, where your user account is held. I turned it off. You may notice that I don't ask for your address when you make a purchase. This is an option at Stripe, who processes your payment. I turned it off.
Still, in diagnosing this issue yesterday I realised how much data I have on this laptop. Again -- see above -- this is largely unavoidable. I run a business, I need to manage the business' data. For example, every quarter I need to download my transactions for tax reporting.
But I can definitely change my behaviour.
Action 1: make customer data more difficult to access
You might think I'd be safer just deleting it, but this data proved very useful in troubleshooting yesterday's issue. Without it I'd have been blind. So I'd rather not delete it; I don't think there's a problem that this would solve.
The problem to solve is that having this stuff sitting in folders on my laptop is too loose.5 It's too easy for something to leak; too easy for me to think of these files in the same way that I think of all my other files. Instead, I need to be acutely aware that when I'm interacting with them that I'm in some special place. I need to be on high alert.
I have created an APFS encrypted disk image and moved all existing customer data to it. It is mounted on-demand. The password is in 1Password and requires a manual copy/paste: I won't store it in my Keychain, so the disk can't ever mount without my explicit action.
Mounting it will forever recall this incident, and I'll be vigilant. I'll do what I need to do and unmount it. There's no chance that I'll make the mistake of pushing something in there up to the cloud.
Action 2: only download what I need
When I download data from these platforms -- say that quarterly tax analysis from Stripe -- my tendency has been to be lazy, and grab everything. As in, choose all the columns, download everything offered.
Because if you're not exactly sure what you need, it's more convenient to have everything to hand than to have to go back and get what you missed.
From today, I'll only download the specific data that I need to do the job. For Stripe's tax analysis, that might be as minimal as the transaction ID, amounts, and the country of purchase. Your name and email address isn't a factor in my reporting a quarterly sales tax total to the Australian Tax Office -- so why even request that in the export?
Action 3: Proactively delete accounts
I still had a Buttondown account that I wasn't using. It still contained thousands of email addresses.
It, and its associated data, has been deleted. If I think of any other similar accounts, I'll delete them.
Action 4: reminders to disable open services
While it proved not to be relevant, I was disappointed to find that I'd left the Listmonk Postgres database console access enabled. This was an unnecessary risk and happened because I simply forgot to disable it when I was finished.
In the future, if I open up anything like this -- which, again, is going to be necessary to run a business -- I'll set a timed reminder for myself to close it when finished.
Action 5: GitHub is not a backup service
I have a tendency to think of GitHub as a useful backup service. Do a quick git push and now the precious data that I just spent all day massaging into shape is copied to the cloud.
This isn't what GitHub is for! Never again, for any data.
Action 6: Compliance/reporting
Thanks to my Discord for flagging the possibility that I might need to register this breach with various national authorities.
I've investigated a few, and this event is below the reporting threshold. GDPR says that I need to keep internal breach logs and learn from the event, which I was already doing. If you're aware of a more strict requirement from your local authority, let me know and I'll gladly comply. Obviously I can't check them all.
What can you do?
You, as in the reader. What can you do to make yourself more safe online?
Lucy and I have been talking for at least a year about producing a (free) video series addressing the basics of online hygiene. We've moved that idea to the top of the list and will start working on it immediately.
I need to get this post published so I won't go into details here, but the two things you can do to put yourself above 99% of everyone else are:
Use a password manager. Allow it to generate random passwords for you, different for every site. This isn't optional in 2026.6
Use unique email addresses for each service that you sign up for. This is more difficult, and introduces complexity.
If you run a small business and need help: we are here. This stuff is difficult: I messed up and I'm supposed to be an expert. Please ask and we will help you.
End of incident review.
100% human. 0% AI. Always.
Footnotes
More accurately, the leaked data took the form of lists of email addresses in a .sh script, which called the aws sesv2 command to send an email. For the sake of simplicity I'll continue to refer to 'CSV files' in the main story; the data is identical, the only difference being a file extension. ↩
Acknowledging that this is a stretch of the definition of 'self-hosting'; the point being that PikaPods provides me the raw instance, and that configuration and management of this instance is my responsibility. They sit between PaaS and SaaS. ↩
I know that's a common mis-reading of Occam's Razor, which actually states that the theorem that introduces the fewest new elements should be considered the most likely. Close enough. ↩
One person has already written me asking why I think storing user data in JDHQ is a good idea. This isn't the post to prosecute that question but briefly: I'm building features that I want. I think you'll find them useful too. If you never want to use them … just don't. ↩
Noting that I don't consider the laptop itself to be an attack vector. It requires my password immediately after being locked, has FileVault full-disk encryption, and has no open Internet ports. ↩
Coincidentally, a friend of Lucy's was hacked last week. They got her Microsoft OneDrive account and everything in it. She's in the process of getting new passports and drivers licences. A true nightmare. Why? Shared passwords. Your password must be unique. ↩
Further to my discovery of the data leak earlier today, I spent most of the day trying to figure out what had happened. Finally, on a walk with Lucy after we knocked off, the lightbulb went off.
I didn't, did I? Surely not.
I did.
I uploaded a .csv containing your email address to a public GitHub repository. (For the non-technical of you: that's just a web page. I published your email address on a web page.)
Good news: not a 'hack' in the traditional sense. Just a dumb mistake.
Bad news: oof. Johnny. So bad.
To you, whose address is now public, I can only offer my humblest and sincerest apology. Unless you know me personally you won't know what this means to me.
Full report to follow
I'll write this up in detail tomorrow. There's a lot to learn.
I haven't mailed everyone affected yet because there hasn't been much to say. I'll send a link to tomorrow's post once it's up.
This morning I received an email from someone whose unique johnnydecimal@example.com address has received a PayPal phishing email. My personal address received the same email.
The email is from no.con**star@ca**a.cl. Its subject is Please confirm your identity.
I am investigating. If you received this email, please forward it to me.
We're going to try to post much more regularly on YouTube this year. At the end of each month I'll post a link to each of our videos.
(It does help us if you 'subscribe' to the channel, in YouTube, even if you never actually go there. I promise I'll never become a like and subscribe! bro.)
There's a lot of beginner-introductory stuff this month, and the start of a Small Business series that we'll continue through the year.
YouTube is a hot mess, unfortunately
On testing this page, I notice that YouTube -- the largest video player on the Internet owned by one of the richest companies -- doesn't actually work. As in, if you're unlucky 👋🏼 you'll be asked to 'sign in to prove you're not a bot' despite being signed in, and there being no button to enable you to sign in.
I've put a link below each of the videos, and longer-term we'll get these loaded up to JDHQ where you can watch ad-free without any of this nonsense.
My apologies. Not my platform.
What filesystem problems am I trying to fix? (2026-02-03)